The Hidden Gap Between AI Pilots and Enterprise-Scale Reality
Enterprise AI deployment has become a strategic priority for organizations seeking productivity gains, operational efficiency, and competitive advantage. Yet despite significant investment, many AI projects never reach production or fail to deliver measurable business value. Most enterprises have already tested copilots, chatbots, predictive models, recommendation engines, or autonomous agents. Yet despite significant investment, a large percentage of AI initiatives never make it into production—or fail to create measurable business value after deployment.
The reality is simple:
Building a model is easy.
Operating AI reliably inside a business is hard.
Organizations often focus heavily on model selection while underestimating the complexity of production infrastructure, data pipelines, governance frameworks, security controls, monitoring systems, and organizational adoption. As a result, promising proofs of concept remain trapped in pilot environments.
At Avinya Labs, we’ve observed a recurring pattern across AI implementation projects: the challenge is rarely the model itself. The real complexity emerges when organizations attempt to integrate AI into existing workflows, governance requirements, compliance frameworks, and production infrastructure. The gap between a successful proof of concept and a production-ready AI system is where most initiatives struggle.
This article explores why AI projects fail to reach production in 2026 and provides a practical roadmap for deploying, scaling, monitoring, and integrating AI systems successfully.
Enterprise AI Deployment Challenges
Most AI initiatives follow a familiar pattern:
- Executive team approves an AI initiative
- Data science team develops a prototype
- Early demonstrations generate excitement
- Pilot succeeds in a controlled environment
- Production deployment stalls
The failure rarely occurs because the model performs poorly.
Instead, organizations discover challenges involving:
- Fragmented enterprise data
- Regulatory requirements
- Security concerns
- Legacy system integration
- Lack of governance
- Operational ownership confusion
- Employee adoption resistance
- Cost management issues
By the time these issues emerge, momentum has often disappeared.
The 8 Most Common Reasons AI Projects Fail
1. Poor Data Quality and Data Readiness
Every AI system depends on data.
Unfortunately, enterprise data is often:
- Inconsistent
- Incomplete
- Duplicated
- Siloed across departments
- Poorly labeled
- Missing governance controls
Many organizations mistakenly assume modern foundation models can compensate for poor data quality.
They cannot.
AI amplifies underlying data problems at scale.
Examples include:
- Incorrect customer recommendations
- Hallucinated responses
- Misleading business insights
- Inaccurate forecasts
Without trusted data foundations, production deployment becomes impossible.
Solution
Establish:
- Centralized data governance
- Data quality monitoring
- Metadata management
- Data lineage tracking
- Master data management
Treat data as infrastructure—not as a byproduct.
2. Lack of AI Governance
Many organizations deploy AI before defining rules for:
- Data access
- Model approvals
- Compliance reviews
- Risk assessments
- Auditability
- Human oversight
This becomes especially dangerous when deploying:
- Generative AI
- Autonomous agents
- Customer-facing assistants
- Financial decision systems
Governance cannot be added later.
It must be embedded from the beginning.
Solution
Create an AI governance framework covering:
- Responsible AI policies
- Risk classification
- Human review checkpoints
- Model approval workflows
- Audit trails
- Regulatory compliance
3. Legacy System Integration Challenges
Most enterprise environments contain:
- ERP platforms
- CRM systems
- Databases
- Internal APIs
- Document repositories
- Workflow engines
AI systems must interact with all of them.
A chatbot that cannot access business systems provides limited value.
An AI agent that cannot trigger workflows remains a demonstration.
Integration not intelligence, is often the real bottleneck.
This challenge is particularly common among enterprises adopting AI for sales operations, procurement, compliance, customer support, finance, and construction workflows. At Avinya Labs, many AI transformation engagements begin not with model development but with mapping existing systems, data flows, and operational processes to identify where AI can be embedded to create measurable business value.
Solution
Build an integration layer using:
- APIs
- Event-driven architectures
- Workflow orchestration platforms
- Service mesh architectures
- Secure connectors
AI should become part of existing workflows rather than existing as a separate technology layer.
4. No Clear Business Ownership
Many AI projects become trapped between departments:
- IT owns infrastructure
- Data teams own models
- Business units own outcomes
- Security owns approvals
When nobody owns end-to-end success, deployment stalls.
AI initiatives require a designated business owner accountable for:
- Adoption
- ROI
- Operations
- Governance
Without ownership, pilots rarely scale.
Solution
Assign:
Business Sponsor + AI Product Owner + Technical Lead
This leadership triad should drive deployment decisions and accountability.
5. Inadequate MLOps and LLMOps Infrastructure
Many organizations build models but lack systems to manage them.
Common gaps include:
- No deployment pipeline
- No version control
- No rollback mechanisms
- No monitoring
- No retraining process
- No evaluation framework
As models evolve, operational complexity increases rapidly.
Solution
Implement MLOps and LLMOps capabilities:
- CI/CD pipelines
- Model registries
- Feature stores
- Automated testing
- Canary deployments
- Continuous evaluation
- Automated retraining workflows
AI should be treated like production software.
6. Security and Compliance Risks
Enterprise leaders increasingly ask:
- Where is our data stored?
- Can prompts leak confidential information?
- Who can access models?
- How are decisions audited?
- What happens during a model failure?
These concerns often delay deployment.
Especially in:
- Banking
- Healthcare
- Government
- Insurance
- Financial services
Security cannot be an afterthought.
Solution
Implement:
- Encryption
- Role-based access controls
- Prompt security controls
- Model access governance
- Data residency policies
- Audit logging
- Threat monitoring
7. Lack of Monitoring After Deployment
Traditional software behaves predictably.
AI systems do not.
Production risks include:
- Data drift
- Model drift
- Hallucinations
- Cost overruns
- Performance degradation
- Prompt injection attacks
Without monitoring, failures remain invisible until customers complain.
Solution
Track:
Technical Metrics
- Latency
- Throughput
- Error rates
- Uptime
Model Metrics
- Accuracy
- Precision
- Recall
- Drift indicators
LLM Metrics
- Hallucination rates
- Response quality
- Grounding scores
- Safety violations
Business Metrics
- Revenue impact
- Cost reduction
- Productivity gains
- Customer satisfaction
8. Organizational Resistance and Change Management Failure
The biggest obstacle is often not technical.
It is human.
Employees worry about:
- Job displacement
- Increased monitoring
- Loss of control
- Workflow disruption
Without trust and involvement, adoption remains low.
Solution
Create:
- AI champions programs
- Internal training initiatives
- Transparent communication
- Human-in-the-loop workflows
- Feedback-driven implementation
AI adoption is a business transformation project not merely a technology deployment.
Learn more about our AI Development Services
What Production-Ready AI Looks Like
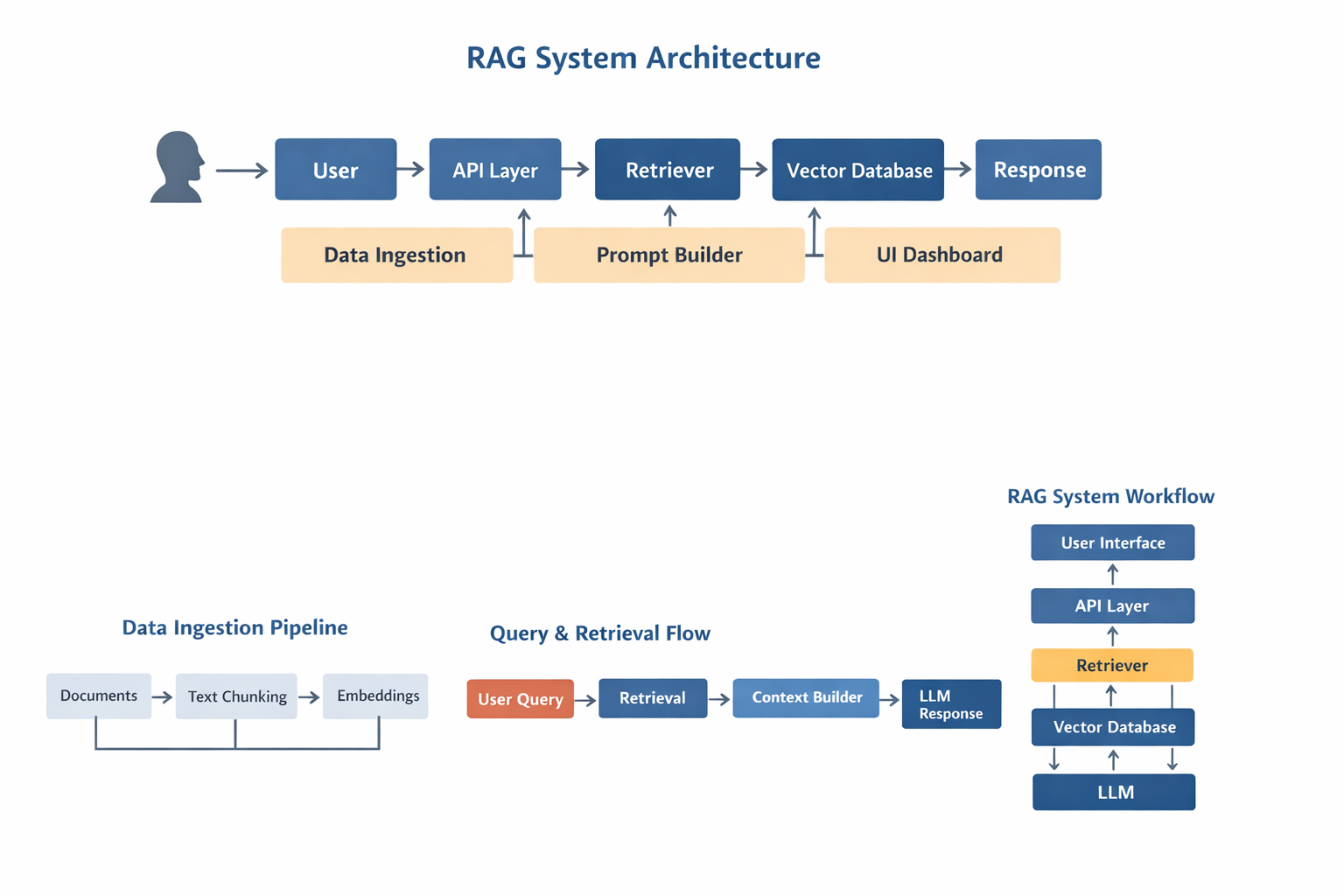
A production-ready AI system is more than a model connected to a user interface. It is an operational layer embedded into business processes, capable of accessing enterprise knowledge, triggering workflows, maintaining audit trails, enforcing governance policies, and continuously improving through monitored feedback loops.
At Avinya Labs, we approach AI implementation as a systems engineering challenge rather than a model deployment exercise. This means designing the complete architecture—from data ingestion and retrieval pipelines to workflow automation, observability, governance, and user adoption—ensuring AI delivers measurable outcomes in real-world environments.
The organizations seeing the highest return on AI investment are not simply deploying models. They are building integrated AI systems that become part of how the business operates every day.
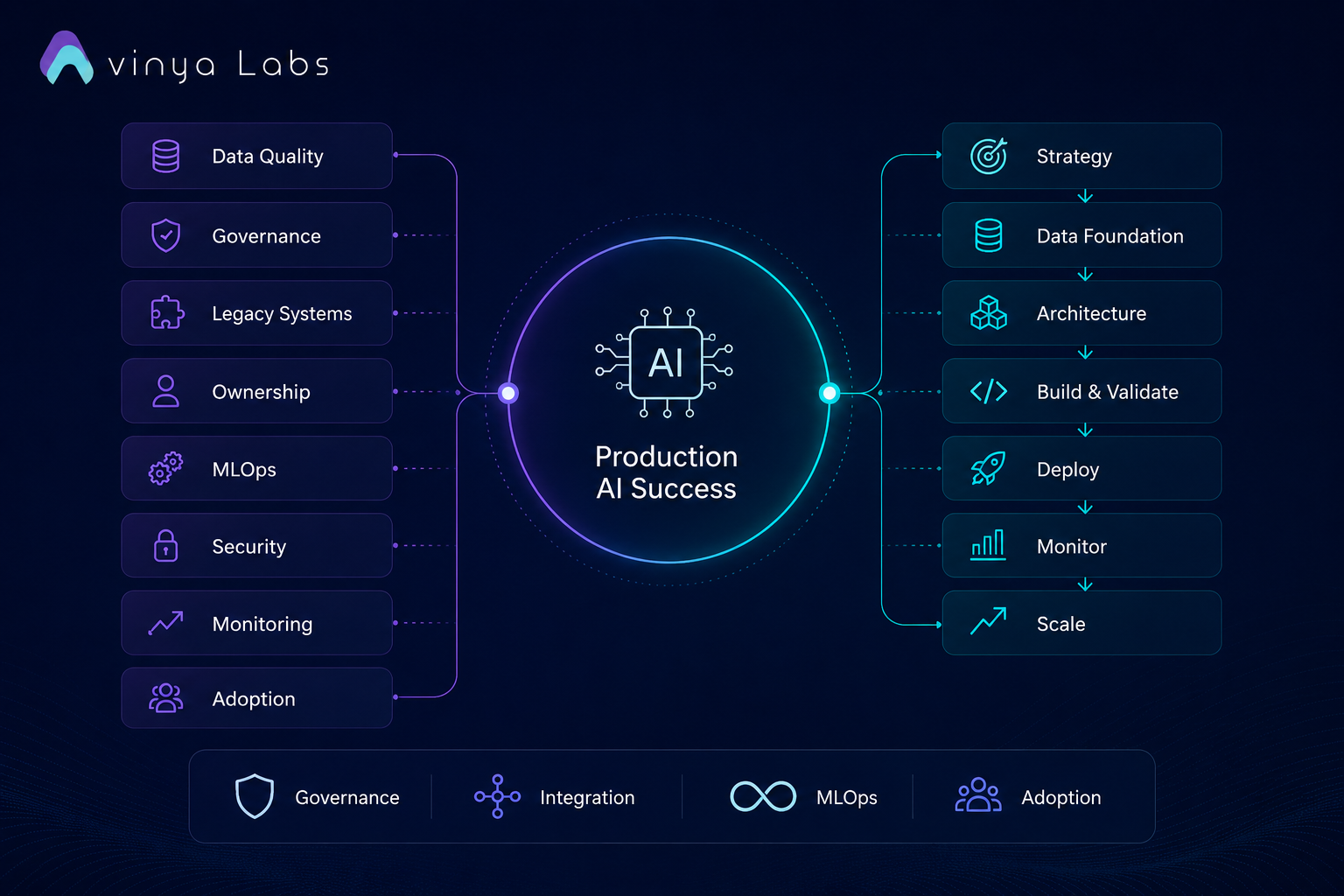
Enterprise AI Deployment Roadmap
Phase 1- Strategy and Opportunity Assessment
Define:
- Business objectives
- ROI expectations
- Success metrics
- Risk profile
- Stakeholder alignment
Questions to answer:
- What problem are we solving?
- How will value be measured?
- Who owns outcomes?
Output
A prioritized AI opportunity roadmap aligned with business goals.
Phase 2 – Data Foundation
Build:
- Data pipelines
- Data governance
- Data quality controls
- Data cataloging
- Access policies
Output
A trusted AI-ready data layer.
Phase 3 – Architecture Design
Design:
- AI application architecture
- Model strategy
- Vector databases
- Knowledge systems
- Security controls
- Integration framework
For organizations beginning their AI journey, partnering with an experienced implementation team can significantly reduce deployment risk. Architecture decisions made at this stage often determine whether a project scales successfully or becomes another isolated pilot.
Output
A production-ready technical blueprint.
Phase 4 – Development and Validation
Build:
- Models
- RAG pipelines
- AI agents
- Business workflows
- Evaluation frameworks
Validate:
- Accuracy
- Safety
- Security
- Compliance
Output
An enterprise-approved AI solution ready for deployment.
Phase 5 – Production Deployment
Deploy using:
- Kubernetes
- Containerized workloads
- API gateways
- Auto-scaling infrastructure
- CI/CD pipelines
Output
A stable production environment.
Phase 6 – Monitoring and Observability
Implement:
- Real-time monitoring
- Drift detection
- Cost tracking
- Security alerts
- Business KPI dashboards
Output
Operational visibility and continuous improvement capabilities.
Phase 7 – Scale and Optimization
Expand:
- Additional use cases
- Departments
- Geographic regions
- Agent capabilities
Introduce:
- Multi-agent orchestration
- Workflow automation
- Autonomous operations
Output
An enterprise-wide AI platform that continuously compounds value.
The Emerging Enterprise AI Stack for 2026
Leading organizations increasingly standardize around five layers:
Application Layer
- AI copilots
- AI assistants
- Autonomous agents
Intelligence Layer
- Foundation models
- Fine-tuned models
- Retrieval-Augmented Generation (RAG)
Knowledge Layer
- Vector databases
- Enterprise knowledge graphs
- Document intelligence systems
Operations Layer
- MLOps
- LLMOps
- Monitoring
- Governance
Infrastructure Layer
- Cloud environments
- Hybrid cloud deployments
- Private AI infrastructure
- GPU compute clusters
Organizations that treat AI as a complete operational stack not a standalone model are significantly more likely to achieve production success.
Enterprise AI Deployment Success Factors
At Avinya Labs, we’ve found that the organizations achieving the greatest return on AI investment are not necessarily those using the most advanced models. They are the ones that treat AI as a business capability—supported by strong data foundations, governance, operational processes, and clear ownership. Production success comes from building the ecosystem around the model, not simply deploying the model itself.
The primary reason AI projects fail in 2026 is not because the models are insufficient.
The real challenge lies in transforming a promising prototype into a reliable business capability.
Successful enterprises recognize that production AI requires five foundations:
- High-quality governed data
- Strong AI governance
- Deep integration with business workflows
- Continuous monitoring and operations
- Organizational adoption and ownership
The companies that master these foundations will move beyond isolated pilots and build AI systems that generate measurable business outcomes at scale.
The future belongs not to organizations that experiment with AI, but to those that operationalize it. And operationalizing AI requires far more than a model, it requires strategy, systems, governance, and execution. That is where enterprise AI transformations are ultimately won or lost.