Introduction
When building AI systems for companies, one of the most common questions is whether to use RAG vs fine tuning for business AI.
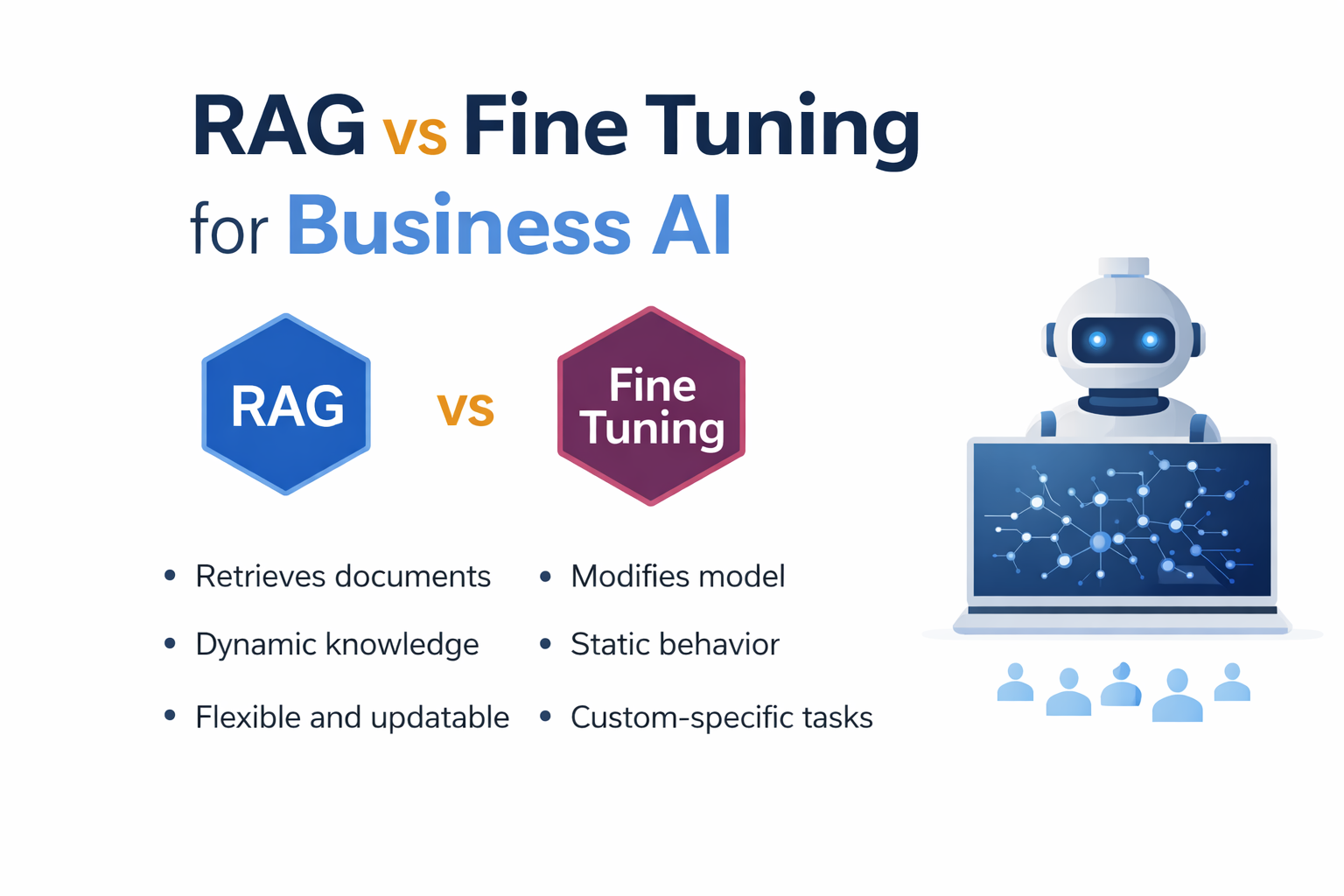
Both approaches allow businesses to customize LLMs, but they solve very different problems. Many SMBs try fine tuning when they actually need retrieval, while others build RAG systems when model training would work better.
Understanding the difference between RAG vs fine tuning for business AI is important when building internal AI tools, knowledge assistants, automation systems, and document search platforms.
RAG vs fine tuning for business AI is one of the most common decisions when building internal AI systems, knowledge assistants, or automation platforms for SMBs.
This guide explains architecture, differences, use cases, and best practices used in real production AI systems.
What is RAG in Business AI
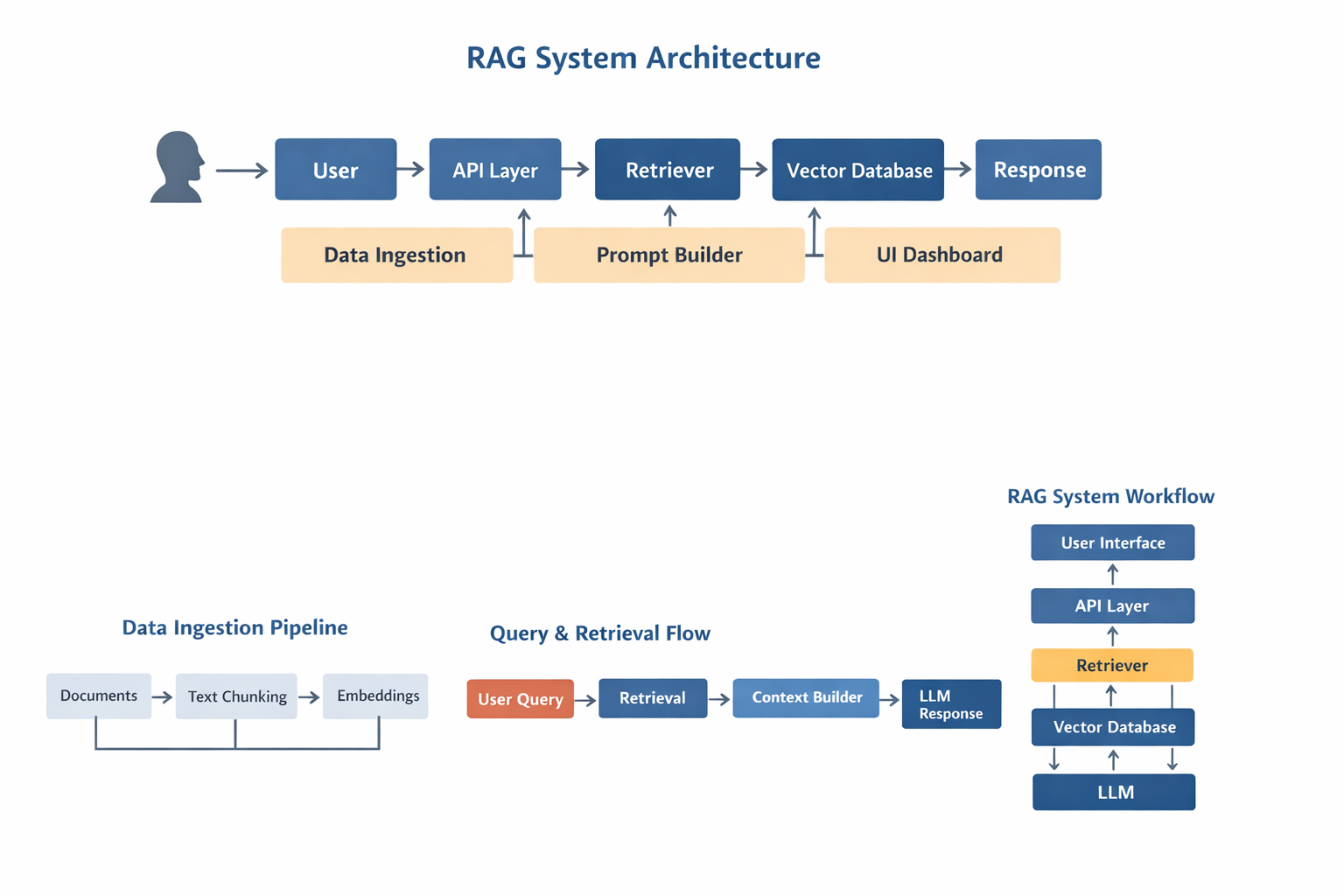
RAG stands for Retrieval-Augmented Generation.
A RAG system retrieves company data at runtime and sends it to the LLM before generating a response.
Flow:
User → Query → Retriever → Vector DB → Context → LLM → Response
RAG is commonly used for:
- company knowledge base
- internal chatbot
- document search
- support AI
- workflow automation
RAG works best when company data changes often.
What is Fine Tuning in Business AI
Fine tuning means training a model on custom data so the model learns behavior, style, or domain knowledge.
Instead of retrieving documents, the model itself is modified.
Fine tuning is used for:
- classification
- structured output
- tone control
- domain language
- scoring models
Companies building internal AI systems often need:
- access to company documents
- knowledge search
- automation logic
- consistent output
- custom behavior
This leads to the decision:
RAG vs fine tuning for business AI.
Choosing the wrong architecture can cause:
- bad answers
- high cost
- slow performance
- hard maintenance
Correct architecture is critical for long-term AI systems.
When to Use RAG
Use RAG when:
- data changes often
- documents are large
- knowledge stored in files
- multiple data sources exist
- real-time search needed
Common SMB use cases:
- internal GPT
- company knowledge base
- support assistant
- SOP search
- HR bot
- document lookup
- proposal generator
RAG is best for knowledge systems.
When to Use Fine Tuning
Use fine tuning when:
- behavior must change
- output must follow format
- domain language needed
- classification required
- consistent answers needed
Examples:
- email classifier
- intent detection
- scoring model
- structured JSON output
- custom chatbot style
Fine tuning is best for behavior.
RAG vs Fine Tuning Architecture Comparison
RAG architecture:
Documents → Embedding → Vector DB
Query → Retriever → Context → LLM
Fine tuning architecture:
Dataset → Training → Model update → Inference
Key difference:
- RAG retrieves data
- Fine tuning changes model
Diagram description:
RAG
User → API → Retriever → Vector DB → LLM
Fine tuning
Dataset → Training → Model → API
Data Flow Comparison
RAG flow:
Query
→ Search
→ Context
→ LLM
→ Answer
Fine tuning flow:
Query
→ Model
→ Answer
RAG is dynamic.
Fine tuning is static.
Hybrid Architecture: Using RAG and Fine Tuning Together
Most real AI systems use both.
Hybrid flow:
User → Agent → Retriever → Vector DB → Context → LLM → Fine-tuned model → Response
Why hybrid works:
- RAG provides knowledge
- Fine tuning provides behavior
- Agents provide automation
Example:
Support AI
RAG → docs
Fine tuning → format
Agent → actions
Hybrid systems are common in production.
Using RAG with AI Agents
Modern AI systems use:
Agents + RAG + Fine tuning
Agents → automation
RAG → knowledge
Fine tuning → behavior
Example:
User → Agent → Tool → RAG → LLM → Tool → Response
Used in:
- workflow automation
- CRM AI
- support AI
- dashboards
- SaaS tools
For SMB AI, this architecture is recommended.
Choosing the Right Vector Database
Popular vector DB:
- Pinecone
- Qdrant
- Weaviate
- Milvus
- PGVector
Pinecone — managed
Qdrant — fast
Weaviate — hybrid search
PGVector — simple
Prompt Engineering in RAG vs Fine Tuning
RAG prompt:
Context + Question + Instructions
Fine tuning prompt:
Question → Model
Bad prompts cause hallucinations.
Best practice:
- limit context
- include metadata
- give rules
- avoid long prompts
Prompt design affects accuracy.
Performance Comparison
RAG depends on:
- retriever
- embeddings
- vector DB
- prompt
Fine tuning depends on:
- dataset
- training
- model
RAG easier to update.
Fine tuning faster inference.
Latency Comparison
RAG latency:
retrieval + LLM
Fine tuning latency:
LLM only
Reduce RAG latency with:
- caching
- smaller chunks
- fast DB
Maintenance Differences
RAG:
update docs
re-embed
re-index
Fine tuning:
retrain
test
deploy
RAG easier for changing data.
Deployment Strategies
Cloud RAG
Hybrid RAG
Local RAG
Fine tuning server
SMB → cloud
Enterprise → hybrid
Monitoring and Logging
Track:
- queries
- context
- errors
- latency
- usage
Production AI needs monitoring.
Real Production Architecture
User → UI
UI → API
API → Agent
Agent → Retriever
Retriever → Vector DB
Vector DB → LLM
LLM → Tool
Tool → Response
Used in real systems.
Why Most SMB AI Systems Start with RAG
Most companies have documents, not datasets.
Typical order:
1 RAG
2 Agents
3 Fine tuning
4 Automation
RAG is usually first step.
Why Avinya Labs
Avinya Labs builds:
- RAG systems
- AI agents
- workflow automation
- custom AI software
- internal dashboards
Serving globally including Dubai, Singapore, Hong Kong.
FAQ
What is the difference between RAG vs fine tuning for business AI
The main difference between RAG vs fine tuning for business AI is how the model gets information.
RAG (Retrieval-Augmented Generation) retrieves company documents at runtime and sends them to the LLM before generating an answer. This makes RAG ideal for knowledge bases, document search, and internal AI tools.
Fine tuning modifies the model itself by training it on custom data. This makes fine tuning better for behavior changes, classification, or structured output.
Most business AI systems use RAG for knowledge and fine tuning for behavior.
When should a company use RAG instead of fine tuning
A company should use RAG when:
- documents change frequently
- knowledge stored in files or databases
- multiple data sources exist
- real-time search is required
- internal knowledge must stay private
RAG is commonly used for company knowledge base systems, internal chatbots, support assistants, and document search tools.
For most SMB AI systems, RAG is the correct starting architecture.
When is fine tuning better than RAG
Fine tuning is better when the model needs to learn behavior instead of retrieving knowledge.
Use fine tuning when:
- output format must be consistent
- classification is required
- domain language is needed
- responses must follow rules
- the same patterns repeat often
Fine tuning works well for scoring models, intent detection, structured responses, and domain-specific AI.
Fine tuning does not replace RAG for knowledge systems.
Can RAG and fine tuning be used together
Yes, modern AI systems often combine both.
Typical architecture:
User → Agent → RAG → LLM → Fine tuned layer → Response
In this design:
- RAG provides knowledge
- Fine tuning controls output
- Agents handle automation
This hybrid approach is common in production AI systems used by SMBs and enterprises.
Is RAG required for internal AI systems
In most cases, yes.
Internal AI systems usually need to access:
- documents
- SOPs
- emails
- databases
- CRM data
- support content
Since this data changes often, RAG is the best architecture.
Without RAG, the model cannot access updated information.
Do AI agents use RAG or fine tuning
Most AI agents use RAG.
Agents need access to company knowledge to complete tasks.
RAG allows agents to retrieve the correct information before calling tools.
Typical agent architecture:
Agent → Retriever → Vector DB → LLM → Tool → Result
Fine tuning may be added for behavior, but RAG is usually required for knowledge.
Is RAG more scalable than fine tuning
RAG is easier to scale when data changes often.
With RAG, you only need to update the vector database.
With fine tuning, you must retrain the model.
RAG scaling involves:
- better retrievers
- faster vector databases
- caching
- index optimization
Fine tuning scaling involves:
- retraining
- evaluation
- redeployment
For most business systems, RAG is easier to maintain.
Can SMBs build RAG systems without training models
Yes.
One advantage of RAG is that it does not require model training.
You can build a RAG system using:
- embeddings
- vector database
- LLM API
- retriever logic
This makes RAG ideal for SMBs that want to use AI without managing training pipelines.
Is RAG secure for company data
Yes, if implemented correctly.
A secure RAG system should include:
- authentication
- document permissions
- encrypted storage
- API security
- logging
The LLM should only receive the retrieved context, not the full database.
Security design is important for internal AI tools.
Should I use RAG, fine tuning, or both
Most production AI systems use all three:
- RAG for knowledge
- Fine tuning for behavior
- Agents for automation
Recommended order for SMB AI:
- Start with RAG
- Add agents
- Add fine tuning if needed
This approach keeps the system flexible and scalable.
Does RAG improve AI accuracy for business use
Yes.
RAG improves accuracy because the model receives real company data before answering.
Without RAG, the model relies only on training data, which may be outdated.
RAG is the main reason modern business AI systems can work with private data.
Can RAG work with local LLMs
Yes.
RAG can work with:
- OpenAI
- Claude
- local LLM
- on-prem models
The architecture stays the same.
Only the LLM changes.
This makes RAG useful for companies with privacy requirements.
What is the best architecture for business AI today
The most common architecture today is:
Agent + RAG + LLM + Tools
This allows:
- knowledge access
- automation
- structured output
- workflow execution
This architecture is used in modern AI platforms, SaaS tools, and internal automation systems.